Foreword
记录一些AI相关的流程或者是运行逻辑
AI
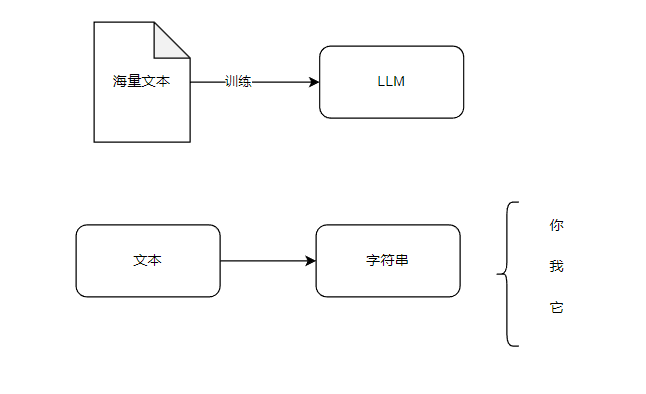
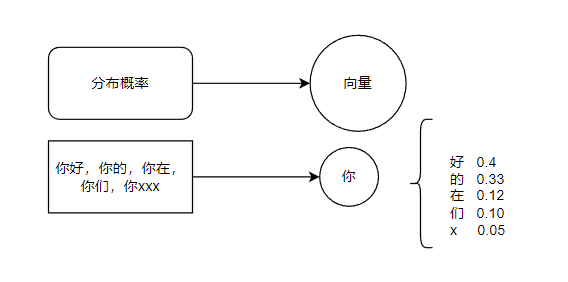
Transform
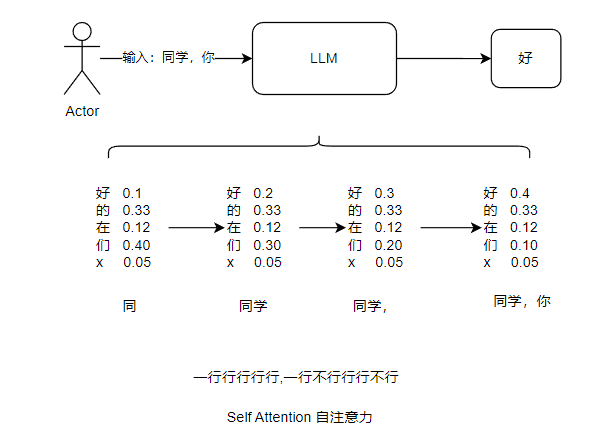
Transform的机制
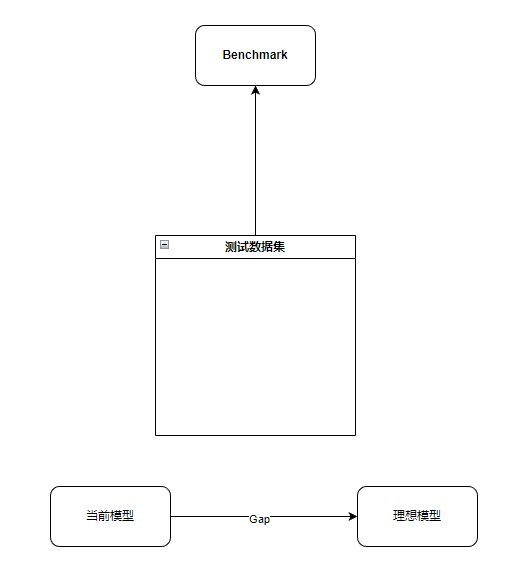
Benchmark
做一个新模型的时候,最好先建立好一个Benchmark,用来评估当前模型的性能,从而有一个准确的优化方向
微调
微调的流程
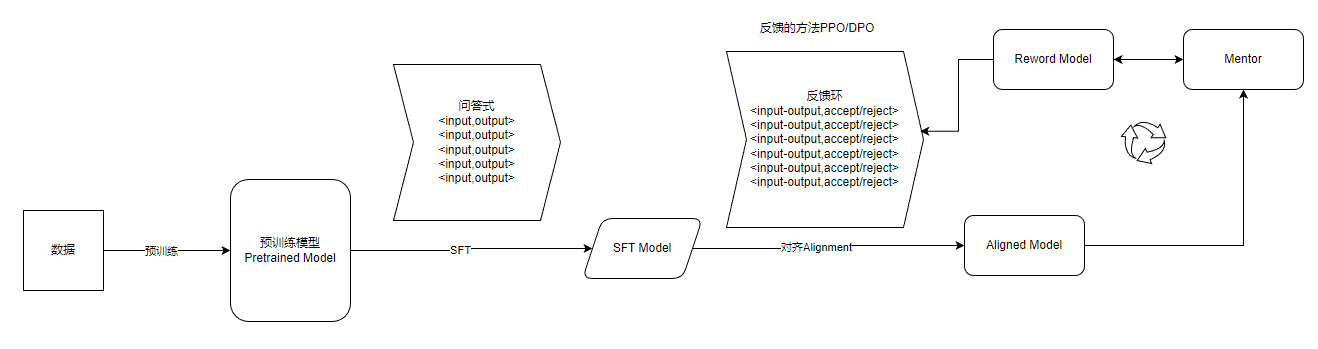
微调的后期,要么是有一个专家模型负责评估,要么就是有一个RLHF的反馈环境,不断对模型进行微调,这样整个模型就在不断进化中,效果就能越来越好。
当这个累计到一定时间或者数据以后,就可以考虑直接全参数微调,变成一个新模型
RAG
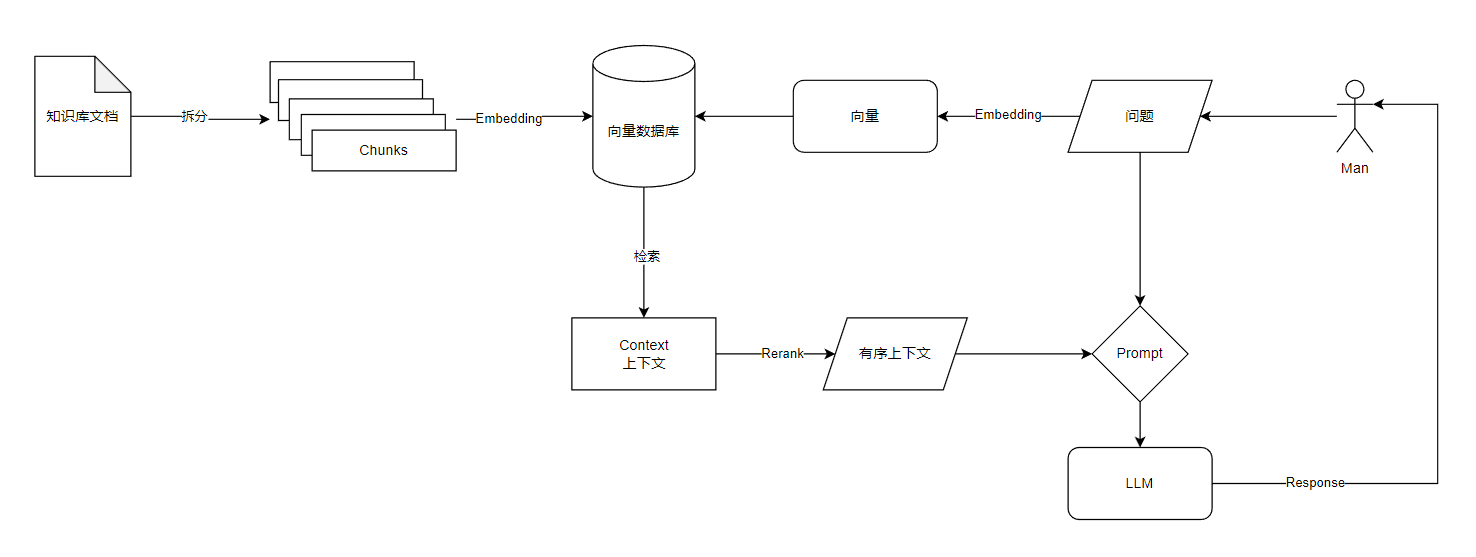
某些应用既可以通过RAG实现,也能通过微调实现,RAG相当于是外挂一个知识给模型,比较灵活,但是RAG的实现细节也有很多东西要考虑。
Denoise
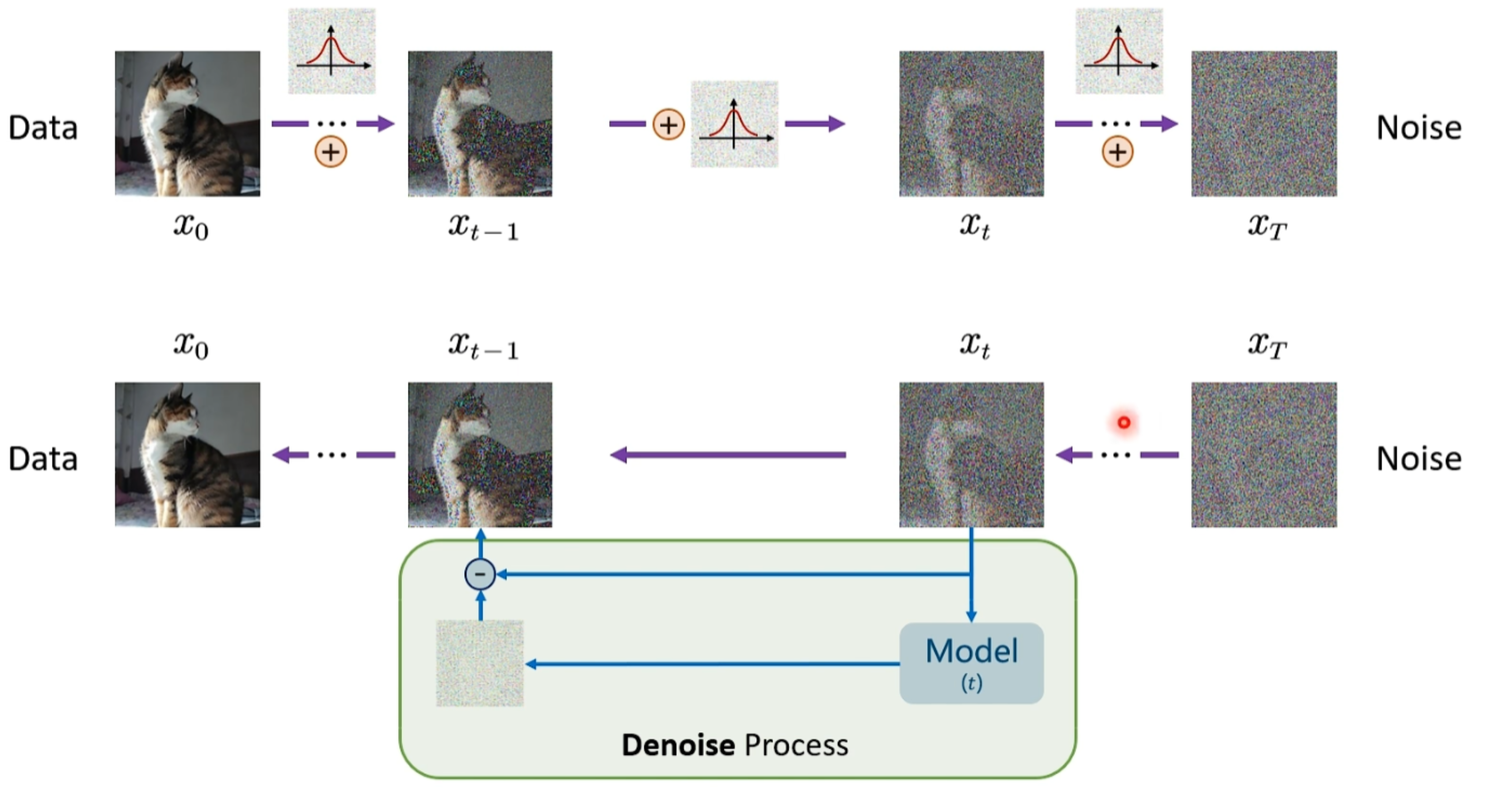
本质上Diffusion就是你给一个图片,然后加高斯噪声,加n轮以后得到了一个结果,然后这个结果和n轮噪声就和原图有了一个对应关系。Denoise 就是将噪声图反推出来原图,这样的训练对越多,最后这个模型的还原能力越强,越接近原图本身,最核心的就是预测噪声。
Stable Diffusion
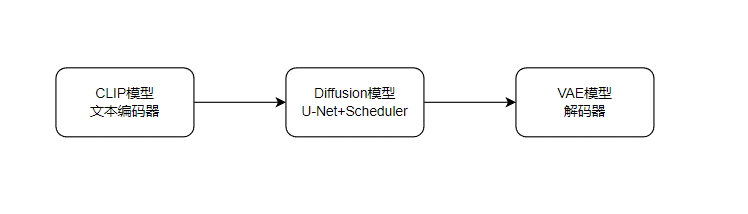
简化以后的SD,大概就是这么三个东西
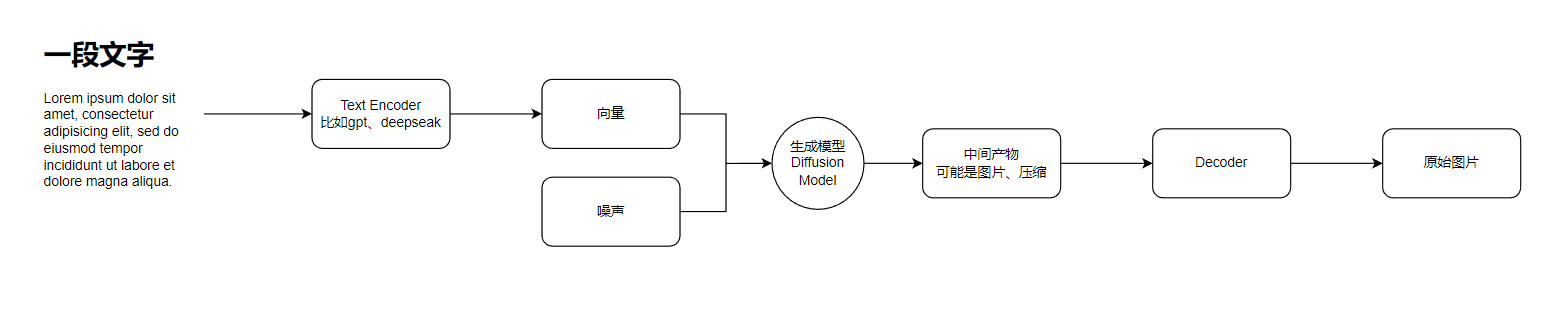
再拆解一下大概就是这样,以我目前的理解,其实就是将图片和文字形成一个映射关系,然后将这个内容在空间中离散化,这样数据量足够大以后,模型就能抽象出来文字和图像的对应关系了,再下一步,则是用户输入了一段文字,那么这段文字需要被离散成SD模型中可以识别的那部分文字向量,然后将他们组合到一起,通过反向去噪,也就是解码,就能得到目标图形了。
这个里面还有一个首要的问题要解决,就是为什么这个去噪能成功,他就能显示目标图像。因为在前面编码阶段,就是将文字向量和图像向量编码成了一种概率模型,如果是其他的东西可能就不行了,他在空间中的分布就是类似噪音式的,所以在后续的解码步骤中才能还原文字中图像的意图
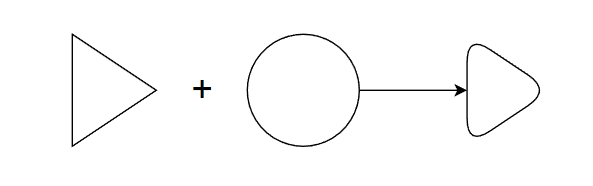
就比如生成一个圆角三角形,本质上并不是死板的把三角和圆强行融合在一起,而是通过概率或者说抽象将三角的这个概念和圆形的曲边进行了概率融合
如果是用SD来一些图像处理流程,比如抠图、换背景、换装、换姿势等等,他们又有各自的流程,这个pipeline更适合ComfyUI来做节点管理,更偏向于现代的节点编程的概念
Summary
简化理解以后大概是这样,实际其中每个环节都值得深挖,有各种策略或者算法来做每个环节
Quote
https://www.bilibili.com/video/BV19f421q7EU
https://www.bilibili.com/video/BV1xih7ecEMb
https://www.bilibili.com/video/BV1ix4y1x7MR