Foreword
DeepSeek火了这么久,总算轮到我来部署一下了,部署小模型的挺多的,但是接近满血的大模型的好像很少,遇到的问题也难得有人说。
DeepSeek
设备需求
浪潮 NF5468M6 GPU服务器
CPU:2x6330(2G,28C/56T,42MB,Turbo,205W,3200),2x2400¥ 内存:32x64G DDR4 3200 RDIMM ECC,32x500¥ 硬盘:5x1.6TB SSD NVMe U.2 2.5寸 混合型,5x900¥ 阵列卡:Intel/英特尔 VROC KEY VROCPREMM0D U.2 NVME 阵列 RAID 0/1/5/10激活卡 高级版,1300¥ 网卡1:迈络思 MCX556A 100G 双口网卡,1500¥ 网卡2:X710双口万兆网卡(含模块),600¥ 显卡:8xNVIDIA Tesla L20 GDDR6 48GB PCIE 350W,8x25500¥ 电源:4x3000W 热插拔电源,双供电、双备份,4x1788¥
主板:NF5468M6,含税44000¥
这么一套单纯硬件(二手)含税合一起大概是32w左右就能拿下了,剩下的基本就是组装、调试、服务、售后的钱了
这一套显存是384g,内存是2048,如果要高速,可以部署 DeepSeek-R1-671B Q4;如果想要充分利用内存,其实可以2个GPU+512G内存来部署一个,这样能部署出来4个,甚至5个,不过速度嘛,肯定是要低一些;如果要满血版本,需要结合内存一起来用,差不多一半内存+一半显存就能跑起来了
nvidia-smi
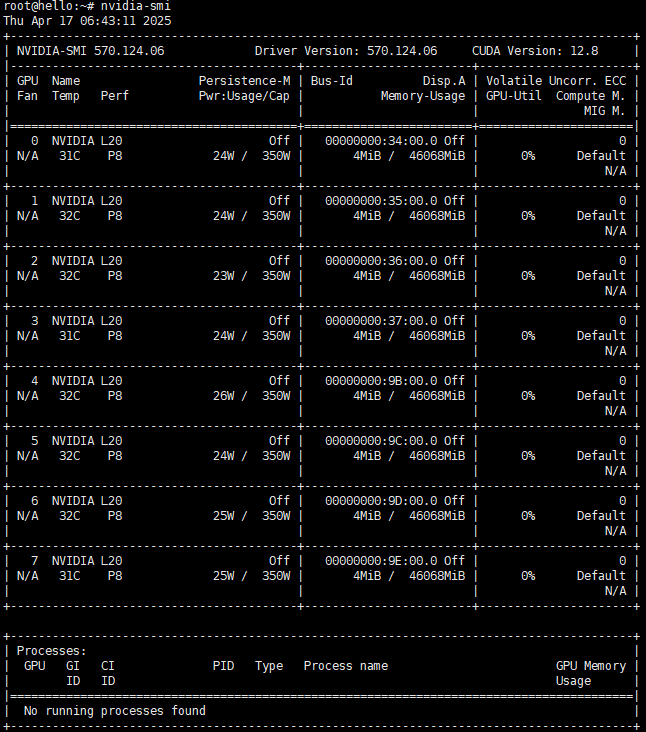
部署
驱动安装
https://www.nvidia.com/Download/index.aspx?lang=cn
官网找到对应驱动,然后下载
查看驱动状态
lspci | grep -i nvidia
查看内核模块,若无输出,说明模块未加载:
lsmod | grep nvidia
查找已经安装的模块
find /lib/modules/$(uname -r)/kernel/drivers -name nvidia*
重新生成模块
sudo apt-get install dkms
重新安装模块,这里驱动版本号要全部的,不能省略
sudo dkms install -m nvidia -v 570.124.06
基础环境
由于是新机器,很多东西没有,所以要先把基础环境配置一下
apt install python3
apt install python3.12-venv
切换到一个新环境
python3 -m venv hgf
source hgf/bin/activate
安装huggingface,然后发现huggingface不能直接部署R1,尴尬了
pip install huggingface_hub
安装docker环境,本想用docker直接启动,发现docker镜像里根本没有满血版本的,有的aixblock那个还是偷你算力的,蒸馏版本倒是挺多的,可以直接拉取
apt install docker.io
安装CUDA
安装CUDA,需要注意可以支持的版本,在nvidia-smi中有显示支持的最高版本,我这里是12.8
- 如果一开始新机器没安装驱动也可以利用CUDA安装,不过概率不高
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
sudo sh cuda_12.8.0_570.86.10_linux.run
由于驱动之前安装过了,所以这里不勾选驱动安装
vi ~/.bashrc
把cuda加入到环境变量中
export PATH=$PATH:/usr/local/cuda-12.8/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.8/lib64
刷新环境
source ~/.bashrc
测试一下
nvcc -V
说明安装正常
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:20:09_PST_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0
安装ollama
安装ollama
curl -fsSL https://ollama.com/install.sh | sh
拉取模型
ollama run deepseek-r1:671b
671b q4大概有404GB,拉取非常费时,建议内部做一个模型库,需要的时候从内部拉,不然每次拉这个东西要好几个小时。

上面直接启动可能跑不起来,这个时候就需要修改一下默认的ollama的配置,用下面的方式来自定义配置
ollama show --modelfile deepseek-r1:671b | sed -e 's/^FROM.*/FROM deepseek-r1:671b/' > Modelfile
可以看到一个类似这样的文件
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM deepseek-r1:671b
FROM deepseek-r1:671b
TEMPLATE """<|User|><|Assistant|><|end▁of▁sentence|><|Assistant|>"""
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>
# 这里是要自定义的
PARAMETER num_gpu 48
# 上下文token数量,过大会消耗非常多显存,慎重调整
PARAMETER num_ctx 131072,默认deepseek是2048
# 响应的token上限 无上限
PARAMETER num_predict -1
- num_gpu,这里其实是指模型的分层,不是具体使用的gpu数量,看起来有点歧义。模型整体大小不同的时候,这个数值所代表消耗的gpu内存也不一样,所以这里需要测试一下多少才行
deepseek-r1的模型是分了61层,这里实测384GB的显存,不改上下文只能开起来48,更大就不行了
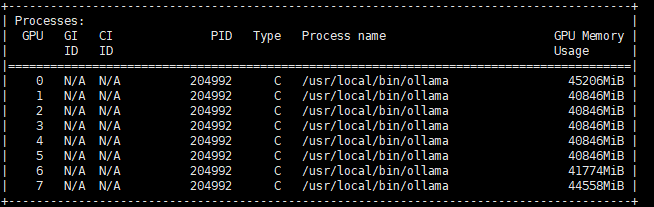
看起来好像没有用满,实际还要结合上下文的大小
如果显存不够用,会出现类似的错误,这种错就去调整num_gpu就可以了
Error: llama runner process has terminated: error loading model: unable to allocate CUDA1 buffer
llama_model_load_from_file_impl: failed to load model
修改完Modelfile以后,就可以创建一个新的模型配置
ollama create deepseek-r1-multi-gpu -f Modelfile
然后启动对应的模型
ollama run deepseek-r1-multi-gpu
正常的情况下就能看到已经可以响应了
root@hello:~# ollama run deepseek-r1-multi-gpu
>>> hello,who are you?
<think>
</think>
Hello! I'm DeepSeek-R1, an artificial intelligence assistant created by DeepSeek. I'm at your service and would be delighted to
assist you with any inquiries or tasks you may have.
>>> Send a
Open WebUI
部署
单独跑起来DeepSeek还不够,还得有个UI界面配合一起用
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
一开始进去以后就需要设置管理员账号密码,设置好了以后可能会发现没有模型,模型相关设置会报错
Open WebUI: Server Connection Error
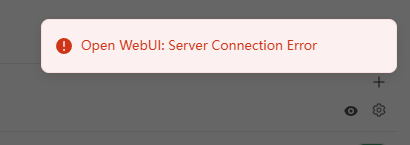
这个主要是ollama本身只允许127.0.0.1的方式访问,而docker访问相当于是跨网络,所以拿不到模型
修改访问接口
停止ollama服务
systemctl stop ollama
修改配置
vi /etc/systemd/system/ollama.service
主要是把OLLAMA_HOST改成任意网络,否则docker访问不到这个位置
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/hgf/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
Environment="OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
重载配置文件
systemctl daemon-reload
systemctl start ollama
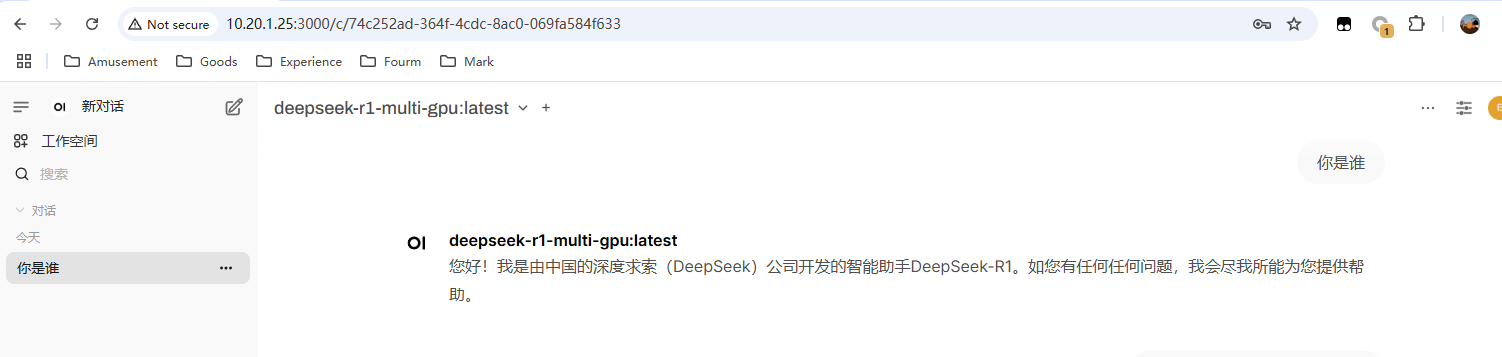
第一次回答,需要启动模型,可能延迟很久,实际第二次回答也不咋快,对比官方或者其他大模型的速度来说
缺少思考
可能还会遇到没有思考过程的问题
https://github.com/open-webui/open-webui/discussions/10685
参考这里,在设置-函数中添加这个函数,然后打开全局使用
class Filter:
detect_reasoning_content = {}
def stream(self, event: dict) -> dict:
event_id = event.get("id")
for choice in event.get("choices", []):
delta = choice.get("delta")
reasoning_value = delta.get("reasoning_content", "")
if reasoning_value:
if self.detect_reasoning_content.get(event_id, False):
delta["content"] = reasoning_value
else:
self.detect_reasoning_content[event_id] = True
delta["content"] = f"<think>\n{reasoning_value}"
elif self.detect_reasoning_content.get(event_id, False):
if event_id in self.detect_reasoning_content:
del self.detect_reasoning_content[event_id]
value = delta.get("content", "")
delta["content"] = f"</think>\n{value}"
return event
就可以看到展示的思考过程了,不过好像还是有问题
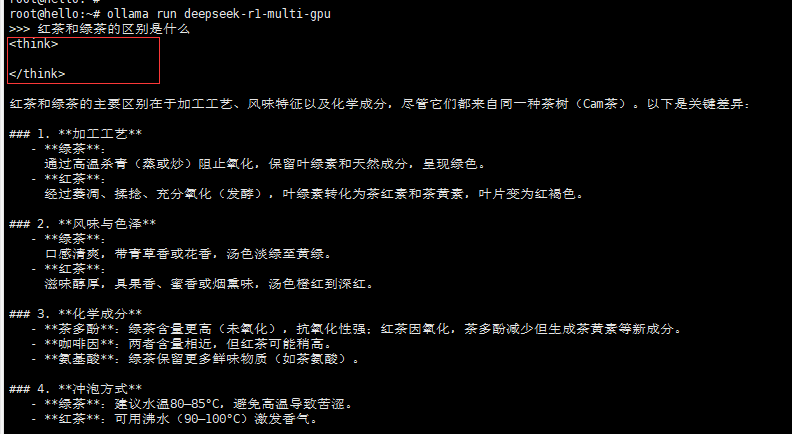
如果这里是空的,那说明这个模型是普通模式,没有开启思考,还要单独打开
- 也有可能问题太简单了,不需要思考,所以空了
测试
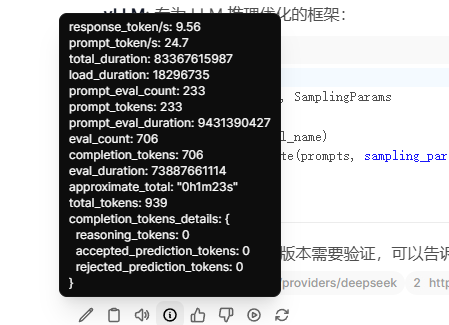
看起来和OpenWebUI一起,token速率只有8-10左右,而且由于OpenWebUI的一些prompt或者默认的设置,经常会触发deepseek变傻,输出一段莫名其妙的官方回复。
目前除了8卡显存用完,还额外用了一些内存

可以通过ollama ps 查看占用情况
root@hello:~# ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1-multi-gpu:latest f1eca30714f3 432 GB 23%/77% CPU/GPU 4 seconds from now
Benchmark
参考另一个博主的测试方式,我也对应测了一下,加上verbose参数,就会显示输出的一些细节信息
ollama run deepseek-r1-multi-gpu --verbose
这个问题竟然正常显示think标签了,有内容了
简述拉格朗日乘子法在生物学中的应用场景。
测试结果
total duration: 2m16.440943797s
load duration: 19.878741ms
prompt eval count: 16 token(s)
prompt eval duration: 539.138037ms
prompt eval rate: 29.68 tokens/s
eval count: 1225 token(s)
eval duration: 2m8.612675382s
eval rate: 9.52 tokens/s
缩短上下文token,我试一下看能否全部加载到GPU,实际还是不行,单纯这个432G的大小就不够,至少得10张卡才行,还有额外的一些缓存或者文件消耗内存,目前这个配置Q4还是不太合适,可以考虑配置动态Q2.51的,那个只用200G就可以。
Summary
后续再测试一下动态Q2.51的模型速度,理论上应该比这个要快一些,现在用起来体验还是很差,虽然给一些小业务够用了。
Quote
https://zhuanlan.zhihu.com/p/23570780393
https://blog.csdn.net/takedachia/article/details/130375718
https://github.com/ollama/ollama/blob/main/docs/modelfile.md#parameter
https://zhuanlan.zhihu.com/p/30049062412
https://www.cnblogs.com/dechinphy/p/18728222/share-memory
https://mp.weixin.qq.com/s?__biz=MzIyNjM2MzQyNg==&mid=2247700014&idx=1&sn=7926c4c9af5ebba7b8d138c8832b32a1&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzIyNjM2MzQyNg==&mid=2247700063&idx=1&sn=3aeb9031728ab8d4ba2f23bb5fe921fd&scene=21&poc_token=HIILAmij7cnPVOGGXNYV4cuIkl2PZLkoiy7020_z
https://blog.csdn.net/qq_40721108/article/details/145797337